这是一个有意思且无聊的问题,之前在网上看到有人问道这个问题,比如说在PHP里面我们写下 $name = "名字" 这样的代码语句,在代码运行的时候,$name 在哪里呢? 了解了变量在内存中存储方式的人会知道,一般变量的值在存放在栈内存里面的,但是名字呢?
针对这个问题,咱们先要区分一下编译型语言和解释型语言,这2种语言运行方式完全不一样,C/C++是典型的编译型语言,而且PHP/JS则是典型的解释型语言。
编译型语言要想运行,必须使用一个编译器去把代码转换成目标平台机器代码。而解释型语言是通过一个解释器实时翻译成一种中间代码一行行运行。前者又被称为静态语言,后者又被称为动态语言。像Java,C#则属于这2种中间,因为他们有一个预编译的过程,会先把代码转换成中间代码存放起来,在Java里面就叫字节码,然后在虚拟机(jvm)里面执行,效率比纯解释执行高。PHP就有一个opcache扩展可以把生成的中间代码opcode缓存起来以提高效率,不必每次运行的时候都生成。
说这么多,想说明一个问题,那就是变量名和变量在这2种语言里面的存储是有区别的,回到最开始的问题,咱先说说经典的C语言:
C语言里面变量和变量名的存储
为了说明这个问题,咱们简单的来说一下C里面变量在内存里面的存储:
1.栈区(stack)— 由编译器自动分配释放 ,存放为运行函数而分配的局部变量、函数参数、返回数据、返回地址等。
2.堆区(heap) — 一般由程序员分配释放, 用来存储数组,结构体,对象等。若程序员不释放,程序结束时可能由OS回收。
3.全局区(静态区)(static)— 存放全局变量、静态数据、常量。程序结束后由系统释放。
4.文字常量区 — 常量字符串就是放在这里的。 程序结束后由系统释放。
5.程序代码区 — 存放函数体(类成员函数和全局函数)的二进制代码。
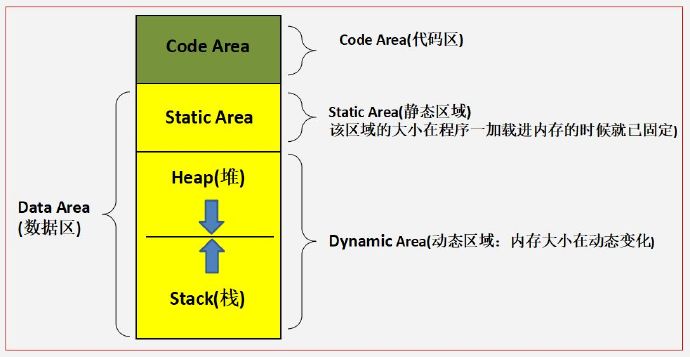
栈内存是有大小限制的,比如默认情况下,Linux平台的是8MB,如果超过这个限制,就会出现 stackoverflow,而堆内存并无限制,内存有多大就可以申请多大。
看完上面的说明,我们可以得出一个结论: 全局变量存放在全局区,在程序一开始就分配好了,而且局部变量在存放在栈区,运行的时候分配内存,用完之后内存会被自动释放。
但是这好像并没有说明变量名在哪里吧?比如下面这段C代码,a, b到底存在哪里?:
1 |
|
为了搞明白这个问题,我们需要了解一下C语言的执行过程,C语言执行需要经过预处理(Preprocessing)、编译(Compilation)、汇编(Assemble)、链接(Linking)等几个阶段,在编译成汇编语言这个阶段就已经没有变量名了,使用gdb可以查看编译后的汇编代码:
1 | (gdb) disass main |
虽然上面这个很难读懂,但是应该能看到在这一大堆汇编指令执行的背后,并没有变量名这个东西,所有的变量名到最后都变成了内存地址,汇编指令操作的是各种寄存器和内存地址。
定义int a;时,编译器分配4个字节内存,并命名该4个字节的空间名字为a(即变量名),当用到变量名a时,就是在使用那4个字节的内存空间。
5是一个常数,在程序编译时存放在代码的常量区存放着它的值(就是5),当执行a=5时,程序将5这个常量拷贝到a所在的4个字节空间中,就完成了赋值操作.a是我们对那个整形变量的4个字节取的”名字”,是我们人为给的,实际上计算机并不存储a这个名字,只是我们编程时给那4个字节内存取个名字好用。
实际上程序在编译时,所有的a都转换为了那个地址空间了,编译成机器代码后,没有a这个说法了。
a这个名字只存在于我们编写的代码中.5不是被随机分配的,而总是位于程序的数据段中,可能在不同的机器上在数据段中的位置可能不一致,它的地址其实不能以我们常用到的内存地址来理解,因为牵扯到一个叫”计算机寻址方式”的问题。
以上的内容有参考网上很多文章,仅供参考!有一点需要明白在操作系统里面,程序的内存地址并不是物理地址,而且通过一个基址+偏移量的方式的计算得到的虚拟地址,操作系统为了更好的管理应用在内存这个层面做了很多抽象。
PHP里面的变量和变量名存储
PHP语句在执行的时候需要zend引擎进行词法分析,语法分析,编译成opcode,opcode可以理解为一种类似机器指令的语句,然后由zend引擎去执行。
有扩展可以打印出生成的opcode,下面看一下:
PHP代码:
1 |
|
opcode结果:
1 | jwang@jwang:~$ php7.0 -dvld.active=1 ~/index.php |
zend引擎会把PHP代码转换成一组op命令操作,上面的就有2组操作。在第一组命令里面可以看到在开始的时候,有一个compiled vars: !0 = $a, !1 = $b, 然后后面有2个ASSIGN操作。可以看到在最终执行的时候并不是使用的$a, $b,而是使用了!0, !1这样的符号去代替。
!0, !1并不是一个固定的值,它每次执行的时候代表的是op命令的操作数。op命令是zend引擎自己定义好的一些操作,具体怎么执行得看zend引擎怎么处理了。
PHP的变量则是通过一个 _zval_struct 结构体形式存储的,讲道理,大部分时候还在存储在堆内存里面的,既然存储在堆里面那么就必须手动释放内存,所以才有了自动垃圾回收机制!
所以,最后总结一下,变量名说到底还是方便程序员编程的,名字起的好便于记忆和阅读代码,就像人一样,名字只是一个代号,本质上只是一堆碳水化合物。
变量名在代码运行的时候都会被一些特殊的符号代替,内存里面并不会有变量名,所以变量名写的长并不会影响运行速度,用中文还是英文也不影响。而变量无论什么类型,最终运行的时候操作的还是内存地址里面数据,变量之所以有类型,是为了方便编译器处理。