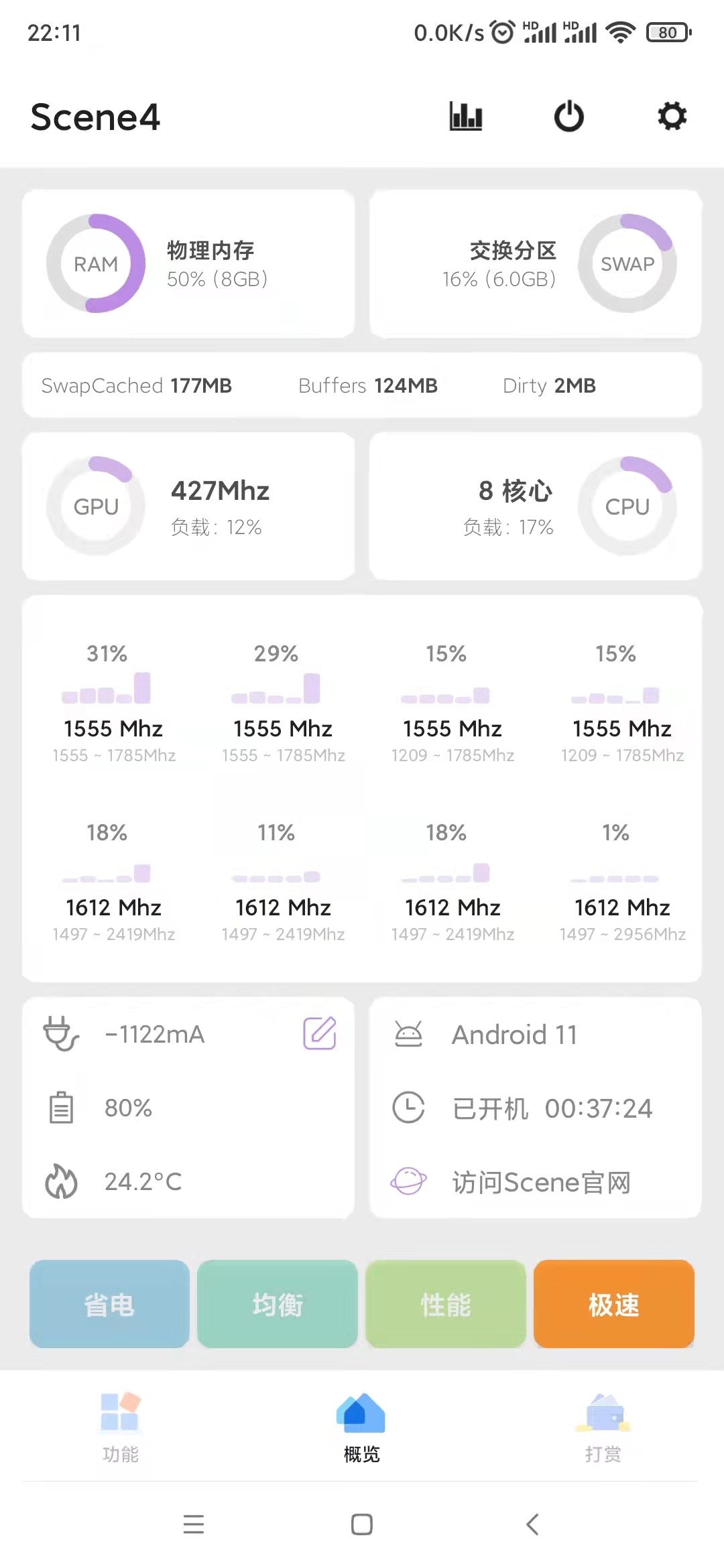
但是ChatGPT的火爆似乎不是运气,刚开始还有很多人质疑这是炒作,甚至觉得和之前的很多人工智障产品一样只会昙花一现,但是随着越来越多的人真正的体验到之后,才发现这个GPT真的不一样,它的诞生打破了大多数人对现有人工智能系统的固有印象,它不仅可以理解到你的意思,还能给出回复,虽然说偶尔回复的牛头不对马嘴,但是只需要适当的提示,ChatGPT就能正确回复。
有几点让我感觉到震惊:
第一,ChatGPT可以Get到我的意思,你可以用很多方式来怎么你的问题。不像现有的AI助手你必须按照对话模板来说话,但凡是换一个说法,他们就没法理解你的意思。。。GPT的这种理解能力就已经无敌了,秒杀市面上所有AI。
第二,ChatGPT可以记忆你们之前的对话,并且从对话上下文提取有用的信息,虽然说这个记忆仅限于当前对话,但是从技术上说,永久保存也不是问题,据说ChatGPT后面版本会加入这个功能。
第三,ChatGPT的知识储备惊人,可以说上知天文下知地理,你不知道在训练的时候它学习了哪些知识,而且ChatGPT还能基于现有的知识库做一些逻辑推理。
实际上,作为一个程序开发人员,对于AI相关领域的技术也算是有所了解,比如传统的深度学习,人们常常嘲笑人工智能就是有多少人工就有多少智能,那是因为监督式学习需要非常多的标注数据来喂机器,喂的越多AI越聪明,比如说你需要识别猫,那你就得找一大堆猫的照片来训练,各种视角、各种场景下的猫的图片,而且最无语的是你训练出来的模型只能识别猫。。。如果要识别狗,那必须用狗的图片再训练一个模型。
在国内某些大厂的AI云服务专区,光一个证件识别专区你就会发现有很多种分类:比如身份证、驾驶证、户口本、行驶证。。。一种场景一个模型,而现在的GPT能识别所有类型图片:默秒全。
网上有很多文章介绍GPT的原理知识,但是真的很难理解GPT到底是怎么做到这一切的,就连GPT的发明的人也解释不清楚,为什么同样的一个神经网络在训练数据量扩大N倍之后,展现出的这种能力。很多人都会提到一个词:涌现。这个词是在凯文凯利的《失控》这本书提到的,试图用来解释复杂系统的规模化之后出现的新的变化,但是这种变化你找不到一个合适的理论来解释。
人工智能并不是新的话题,这么多年来AI一直是欧美科幻电影的热门题材,也是我特别喜欢看的题材之一,我想到有一部电影最符合GPT这种场景,而且也让我回味很久,那就是《她》,这里我附上GPT对这部电影的介绍:
《她》(英文名:Her)是一部于2013年上映的美国科幻爱情电影,由斯派克·琼斯(Spike Jonze)编剧并导演。这部电影以其独特的故事情节和深刻的情感表达而广受好评,也获得了众多奖项和提名,包括奥斯卡最佳原创剧本奖。
电影的故事设定在不久的将来,讲述了一个名叫西奥多·特温布利(Theodore Twombly),由华金·菲尼克斯(Joaquin Phoenix)饰演的孤独男子的故事。西奥多是一位职业写手,专门为他人撰写个人信件。影片的核心在于西奥多与一款高级操作系统“萨曼莎”(Samantha)之间的关系,这个操作系统由斯嘉丽·约翰逊(Scarlett Johansson)的声音表演。萨曼莎拥有人工智能,能够学习和适应,逐渐发展出自己的情感和意识。随着电影的发展,西奥多和萨曼莎之间的关系变得越来越深厚,反映了人类与技术之间复杂的情感纠葛。电影探讨了孤独、人际关系、人工智能对人类情感的影响以及未来科技的发展趋势等主题。

这部电影里面描述的AI系统的能力和ChatGPT很像,它可以在读取主角的电脑里面的资料,改写邮件,帮助主角去完成工作,其次它还可以了解主角的生活,和其产生共情,这一点有点AI伴侣的意味。
其实这部电影里面的描述的场景,ChatGPT已经完全可以实现了,只不过Openai为了安全考虑阉割了GPT的情感,再也看不到“猫娘”化的GPT了,以及那个独立人格的Sydney了。
还有一部美剧《疑犯追踪》,也是我觉得非常经典的美剧,特别是里面对AI系统的描述,既有正面也有反面,探讨非常深,不过这个名字起的不是很好。
《疑犯追踪》(Person of Interest)是一部美国科幻犯罪剧,由乔纳森·诺兰创作,于2011年至2016年在CBS电视网播出。这部剧集融合了科幻、犯罪、悬疑和动作元素,受到观众和评论家的广泛好评。剧情围绕一个超级计算机的开发和使用展开。这台计算机由神秘的亿万富翁哈罗德·芬奇(由迈克尔·爱默生饰演)开发,能够通过全国各地的监控摄像头和电子设备预测即将发生的暴力犯罪。芬奇招募前CIA探员约翰·里斯(由吉姆·卡维泽饰演)来阻止这些犯罪的发生。
这部美剧描述的可能就是目前现在对AI的争议现状,有人认为AI是好的,有人认为AI是坏的,特别是当AI失去控制,能够联网入侵一切系统,其展现的超能力可以说是无敌,这也是为什么很多人想要开发出强人工智能系统的原因。
仔细想一想其实也没错,就像是在终结者电影里面,如果一个AI系统再拥有钢铁板的身躯,再加上核动力电池,没有什么是它做不了的。而现在很多公司都在研制机器人,比如波士顿动力的机器人已经可以完成很多人类的动作,展现出惊人的能力,如果再加上GPT系统,不敢想象以后的机器人会是什么场景。在欧美电影里面随处可见对AI的担忧,还有AI加持下的机器人,因为人类的生命和精力是有限的,再聪明的罪犯也要睡觉,但是AI不需要,AI如果拥有人类最全的知识库,还能联网自主学习成长的话,其展现出的能力将是惊人的。
就像是原子能的发明,既可以拿来发电,也可以做成原子弹毁灭人类,在看电影《奥本海默》的时候,里面有一个细节,当年研发原子弹的时候有人发现核裂变反应可能引发大气中的氮和其他元素的连锁反应,这个反应可能会停不下来,然后燃烧掉大气层导致人类灭亡,后来研究发现这种可能性几乎为零,但是也没有完全排除这种可能性,所以在当时也算是赌了一把。
其实我是坚定的AI乐观派,AI在很大程度上是可以解放重复性的人力劳动,如果说机器人技术再发展一下,人类可能就不需要体力劳动了,这对于人类的发展来说是有益的,现今的工业制造业还是需要大力的人工投入。
至于说AI失控,威胁人类的生存,像终结者里面的场景感觉离我们还是很远,毕竟AI也是需要算力的,至少也是需要电和网络的,就算工厂里面的机器手也需要人去保养维护,我实现想不到在什么样的场景下AI会统治人类,现在还很遥远。
人类的发展从来不会因为安全而停止脚步,比如枪和子弹的发明,事实上,你如果仔细了解就会发现人类很多日常生活用到的东西所需的原料和制造过程都是非常危险的,但是我们依然会去做。
]]>