问: “有10亿个不重复的无序的数字,如果快速排序?”
原理
面试中经常会问到类似问题,看上去很简单,就是一个排序而已,但是你好好想想大部分排序算法都需要把数据放到内存里面操作,这10亿个数字得占用多少内存?好吧,你可以使用外部排序算法,在磁盘上完成排序!当然这些传统算法肯定是可以解决的,不过这里有一个更好的方案,采用bitmap排序,介绍如下:
bitmap是什么? 大家都知道在计算机中一个字节(byte) = 8位(bit), 这里的bit就是位,数据的最小表示单位,map一般是表示地图或者映射,加一起叫作位图?貌似不太形象
简单回顾一下二进制的一些知识:
1byte = 8bit
一个bit有2种状态,0 或者 1
所以1个byte可以表示0000 0000 -> 1111 1111, 也就是十进制的 0 到 255
其中十进制和二进制对应关系如下:
1 | 0 ---------> 0000 0000 |
在大部分编程语言里面,int类型一般的都是占4个byte,也是32位,甭管你这个数字是1 或者是 21亿你都得占32位,所以如果你现在有10亿数字需要存放在内存里面,需要多少内存呢?
1000000000 * 4 / 1024 / 1024 = 3800MB,大概需要3800MB内存,这里计算出的数值只适合C,在PHP里面,一个整型变量占用的实际空间远远大于4byte,是好几倍!
为了解决这个问题,bitmap采用了一种映射机制,举个例子,假如有 1,3, 7,2, 5 这5个数字需要存放,正常情况下你需要5*4=20byte,但bitmap只需要1byte,它是咋做到呢?
假设下面是1byte,首先将所有位置为0:
0 0 0 0 0 0 0
从第一个0开始数数,把对应数字的位置置为1,比如说第一个1那就是第2个位置置为1,第二个3就是把第4个位置置为1,依此论推…
1 | 1 => 0 1 0 0 0 0 0 0 |
叠加起来最终的串就是:
1 | 0 1 1 1 0 1 0 1 |
其实最终的数字和二进制没有什么关系,纯粹是数数,这个串就可以代表最大到7的数字,然后我们就开始数数,从0开始:
1 | 比如第1个位置是1,那就记个1 |
结果就是 1 2 3 5 7,不仅仅排序了,而且还去重了!如果按照这种转换机制,1个int类型,32位的话,可以表示0-31之间的数字!
如果你们要表示最大1万的数,那就需要1万个位的串,但是编程语言并没有这样的数据类型,但是可以用数组去模拟
举个例子:一个整型是32位,也就说我们大概需要314个数组元素来表示这个串
数组第1个元素 00 - 31
数组第2个元素 32 - 63
数组第3个元素 64 - 95
数组第4个元素 96 - 127
…
…
提到这个算法的好处,最大的好处就是节省内存,节省了好几十倍,适合处理大量数据,除了快速排序,还可以做快速去重,快速查询是否存在,还有一个比较好听的应用 Bloom Filter(布隆过滤器):
Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注:如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。
Bloom Filter 在判断y是否属于这个集合时,对y应用k次哈希函数,若所有hi(y)的位置都是1(1≤i≤k),就认为y是集合中的元素,否则就认为y不是集合中的元素。
代码
下面是这个算法的一些演示代码:
1 | <?php |
由于这里面涉及很多位运算操作,所以先回顾一下位操作:
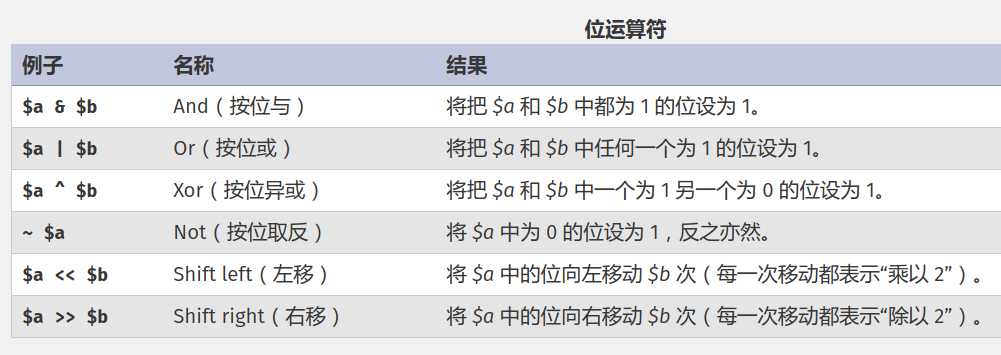
此算法的实现是参考一个C语言版本的,简单解析一下:
第一步,是初始化一个数组,这个数组的长度是根据最大的元素的值来的,比如说你要存一个最大10000的数,由于每个元素最多32位,所以需要大概314个数组。
第二步,初始化数组中的每个元素,把每个位都置成0,在PHP里面其实不需要,但是C里面是必须的,使用了clear这个函数。
SHIFT 是表示位移的位数,之所以是5是因为2的5次方是32,简单的说 $n >> self::SHIFT 这个操作是为了找到当前元素在哪个数组!
MASK 是表示掩码,0x1F是 十进制的31,1 << ($n & self::MASK) 这个操作是计算出当前元素在对应数组里面位置!
举个例子,当前元素是100,按照算法,是在第3个数组里面,下标为4的位置,大家仔细推敲一下,结果确实是这样!只不过这里运用了不少位操作,所以理解起来可能会麻烦一点。
REDIS bitmap相关应用
自己造轮子太累,redis提供了类似的命令,最大可以存放2的32次方,即21亿多的数字,主要有以下几个:SETBIT, GETBIT, BITCOUNT, BITOP, BITPOS,BITFIELD,
主要用来做活跃用户在线状态、活跃用户统计、用户签到等场景,特别适合大量用户,几千万上亿级别,当然你用传统数据库也能做,但是redis做起来更简单,更节省空间!
下面举一个用户签到的功能设计案例:
很多App都有一个签到功能,比如说连续签到7天或者30天给一些奖励,需求十分简单!
作为后端,我们需要提供一个签到接口,然后记录用户签到的信息,比如用户uid,签到时间!
如果使用传统关系型数据库,我们可能需要建一张签到表,大概有id、uid、createdTime等几个字段,当用户签到的时候新增一条记录就行!这种做法肯定是没问题的,但是如果网站每天有千万用户签到,那么这张表每天都会有千万条记录产生,数据的存储是问题!分库分表必不可少!
假如使用redis的bit操作,我们可以使用setbit,SETBIT key offset value 对指定的key的value的指定偏移(offset)的位置1或0, 其中key我们可以设置为当天的年月日,offset是用户uid(这里暂时只考虑uid是纯数字的情况),value的话1表示已签到。比如说用户uid位12500的用户在20190501签到了,我们可以执行SETBIT 20190501 12500 1,其它用户依此论推!
如果我们需要查询用户某天是否签到,只需要使用GETBIT 20190501 12500,返回1表示已签到,0未签到。
如果需要查询某天有多少人签到,可以使用BITCOUNT 20190501。
如果要统计连续7天签到的总人数的话可以使用bitop命令,比如bitop AND 7_dasy_sign 20190501 20190502 20190503 ... 20190507。
理论上讲,setbit的大小在0到2的32次方(最大使用512M内存)之间,即0~4294967296之间,也就说最多可以存储42亿用户的签到情况。和数据库相比,这种方式查询的效率非常高,并不会因为数据大而变慢,而且比较节省内存,操作上也不是太复杂!